 1K+ Reviews
1K+ ReviewsInstructor-Led Training Parameters
Course Highlights
- Instructor-led Online Training
- Project Based Learning
- Certified & Experienced Trainers
- Course Completion Certificate
- Customized Learning Schedule
- Doubt-Clearing Sessions
SPSS Training Course Overview
SPSS (Statistical Package for the Social Sciences) training guides you through the fundamentals of research methods and statistics before moving on to the use of SPSS. SPSS is a powerful statistical application package from IBM used for analysis of data. The training delivers the skill related to the use of SPSS environment for data understanding, data preparation, and ways of executing sequence of operations to derive the result in the required format.
By the end of this training, you’ll be proficient in the following:
- Understanding the research process and be clear in which type of data you must collect and how to measure it
- Differentiating among different statistical models and types of results and errors
- Familiar with SPSS environment
- Know how to use SPPS to work with graphs
- Exploring groups of data and making assumptions to work on a problem
- Use SPSS forvarious statistical procedures such as Correlation, Regression, Dependent and Independent T-test, Pearson Chi-Square
- Compare Means,and conduct post hoc test
- Run several tests for statistical significance and interpreted the results
- Researchers
- Data architects
- Data scientist
- Data analyst
- Decision makers
The candidates having basic knowledge of statistics and computers are ideal for this training.
Instructor-led Training Live Online Classes
Suitable batches for you
| Jul, 2026 | Weekdays | Mon-Fri | Enquire Now |
| Weekend | Sat-Sun | Enquire Now | |
| Aug, 2026 | Weekdays | Mon-Fri | Enquire Now |
| Weekend | Sat-Sun | Enquire Now |
SPSS Training Course Content
1: Research methods
- Statistics?
- The Research Process
- Initial Observation
- Generate Theory
- Generate Hypotheses
- Data collection to Test Theory
-
- What to measure
- How to Measure
-
- Analyze data
- Descriptive Statistics: Overview
- Central Tendency
- Measure of variation
- Coefficient of Variation
- Fitting Statistical Models
- Conclusion
2: Statistics
- Building statistical models
- Types of statistical models
- Populations and samples
- Simple statistical models
- The mean as a model
- The variance and standard deviation
- Central Limit Theorem
- The standard error
- Confidence Intervals
- Test statistics
- Non-significant results and Significant results:
- One- and two-tailed tests
- Type I and Type II errors
- Effect Sizes
- Statistical power
3: SPSS Environment
- Accessing SPSS
- To explore the key windows in SPSS
- Data editor
- The viewer
- The syntax editor
- How to create variables
- Enter Data and adjust the properties of your variables
- How to Load Files and Save
- Opening Excel Files
- Recoding Variables
- Deleting/Inserting a Case or a Column
- Selecting Cases
- Using SPSS Help
4: Exploring data with graphs
- The art of presenting data
- The SPSS Chart Builder
- Histograms: a good way to spot obvious problems
- Boxplots (box–whisker diagrams)
- Graphing means: bar charts and error bars
- Simple bar charts for independent means
- Clustered bar charts for independent means
- Simple bar charts for related means
- Clustered bar charts for related means
- Clustered bar charts for ‘mixed’ designs
- Line charts
- Graphing relationships: the scatterplot
- Simple scatterplot
- Grouped scatterplot
- Simple and grouped -D scatterplots
- Matrix scatterplot
- Simple dot plot or density plot
- Drop-line graph
- Editing graphs
5: Exploring assumptions
- What are assumptions?
- Assumptions of parametric data
- The assumption of normality
- Quantifying normality with numbers
- Exploring groups of data
- Testing whether a distribution is normal
- Kolmogorov–Smirnov test on SPSS
- Output from the explore procedure
- Reporting the K–S test
- Testing for homogeneity of variance
- Levene’s test
- Reporting Levene’s test
- Correcting problems in the data
- Dealing with outliers
- Dealing with non-normality and unequal variances
- Transforming the data using SPSS
6: Correlation
- Looking at relationships
- How do we measure relationships?
- Covariance
- Standardization and the correlation coefficient
- The significance of the correlation coefficient
- Confidence intervals for r
- Correlation in SPSS
- Bivariate correlation
- Pearson’s correlation coefficient
- Spearman’s correlation coefficient
- Kendall’s tau (non-parametric)
- Biserial and point–biserial correlations
- Partial correlation
- The theory behind part and partial correlation
- Partial correlation using SPSS
- Semi-partial (or part) correlations
- Comparing correlations
- Comparing independent rs
- dependent rs
- Calculating the effect size
- How to report correlation coefficients
7: Regression
- An introduction to regression
- Some important information about straight lines
- The method of least squares
- Assessing the goodness of fit: sums of squares, R and R2
- Doing simple regression on SPSS
- Interpreting a simple regression
- Overall fit of the model
- Model parameters
- Using the model
- Multiple regression: the basics
- An example of a multiple regression model
- Sums of squares, R and R2
- Methods of regression
- How accurate is my regression model?
- Assessing the regression model I: diagnostics
- Assessing the regression model II: generalization
- How to do multiple regression using SPSS
- Some things to think about before the analysis
- Main options
- Statistics
- Regression plots
- Saving regression diagnostics
- Interpreting multiple regression
- Descriptive
- Summary of model
- Model parameters
- Excluded variables
- Assessing the assumption of no multicollinearity
- Casewise diagnostics
- Checking assumptions
- What if I violate an assumption?
- to report multiple regression
8: Categorical predictor in multiple regression
- Dummy coding
- SPSS output for dummy variables
9: Logistic regression
- Background to logistic regression
- What are the principles behind logistic regression?
- Assessing the model: the log-likelihood statistic
- Assessing the model: R and R2
- The Wald statistic
- The odds ratio: Exp (B)
- Methods of logistic regression
- Assumptions
- Incomplete information from the predictors
- Complete separation
- Overdispersion
- Binary logistic regression
- The main analysis
- Method of regression
- Categorical predictors
- Obtaining residuals
- Interpreting logistic regression
- The initial model
- Step: intervention
- Listing predicted probabilities
- Interpreting residuals
- Calculating the effect size
- How to report logistic regression
- Testing assumptions
- Testing for linearity of the logit
- Testing for multicollinearity
- Predicting several categories: multinomial logistic regression
- Running multinomial logistic regression in SPSS
- Statistics
- Other options
- Interpreting the multinomial logistic regression output
- Reporting the results
10: Comparing two means (t-test)
- Looking at differences
- A problem with error bar graphs of repeated-measures designs
- Step : calculate the mean for each participant
- Step : calculate the grand mean
- Step : calculate the adjustment factor
- : create adjusted values for each variable
- The t-test
- Rationale for the t-test
- Assumptions of the t-test
- The dependent t-test
- Sampling distributions and the standard error
- The dependent t-test equation explained
- The dependent t-test and the assumption of normality
- Dependent t-tests using SPSS
- Output from the dependent t-test
- Calculating the effect size
- Reporting the dependent t-test
- The independent t-test
- The independent t-test equation explained
- The independent t-test using SPSS
- Output from the independent t-test
- Calculating the effect size
- Reporting the independent t-test
- Between groups or repeated measures?
- The t-test as a general linear model
11: Comparing several means: ANOVA (GLM)
- The theory behind ANOVA
- Inflated error rates
- Interpreting f-test
- ANOVA as regression
- Logic of the f-ratio
- Total sum of squares (SST)
- Model sum of squares (SSM)
- Residual sum of squares (SSR)
- Mean squares
- The f-ratio
- Assumptions of ANOVA
- Planned contrasts
- Post hoc procedure
- Running one-way ANOVA on SPSS
- Planned comparisons using SPSS
- Post hoc tests in SPSS
- Output from one-way ANOVA
- Output for the main analysis
- Output for planned comparisons
- Output for post hoc tests
- Calculating the effect size
- Reporting results from one-way independent ANOVA
- Violations of assumptions in one-way independent ANOVA
12: Chi-square
- Analysing categorical data
- Theory of analysing categorical data
- Pearson’s chi-square test
- Fisher’s exact test
- The likelihood ratio
- Yates’ correction
- Assumptions of the chi-square test
- Doing chi-square on SPSS
- Running the analysis
- Output for the chi-square test
- Breaking down a significant chi-square test with standardized residuals
- Calculating an effect size
- Reporting the results of chi-square

Request for Enquiry
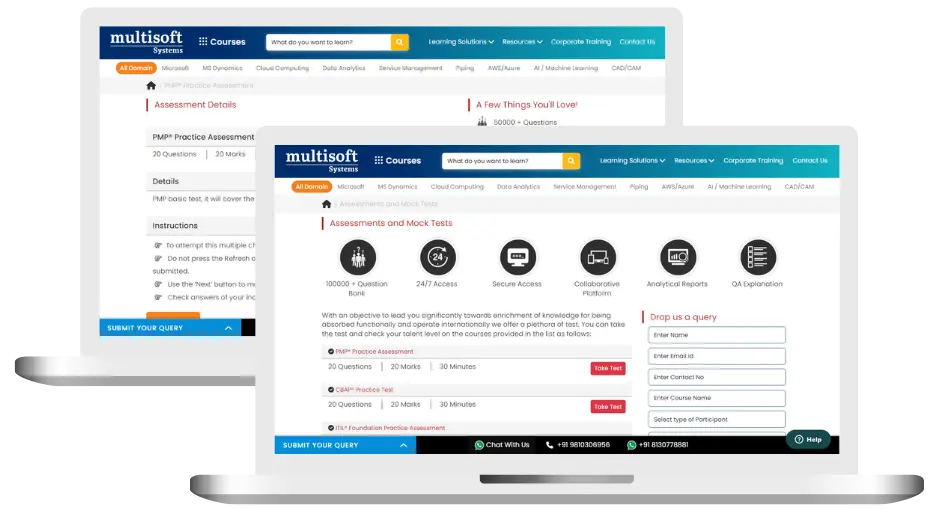
SPSS Training (MCQ) Assessment
This assessment tests understanding of course content through MCQ and short answers, analytical thinking, problem-solving abilities, and effective communication of ideas. Some Multisoft Assessment Features :
- User-friendly interface for easy navigation
- Secure login and authentication measures to protect data
- Automated scoring and grading to save time
- Time limits and countdown timers to manage duration.
SPSS Corporate Training
Employee training and development programs are essential to the success of businesses worldwide. With our best-in-class corporate trainings you can enhance employee productivity and increase efficiency of your organization. Created by global subject matter experts, we offer highest quality content that are tailored to match your company’s learning goals and budget.
Global Clients



Customized Training
Be it schedule, duration or course material, you can entirely customize the trainings depending on the learning requirements
Expert
Mentors
Be it schedule, duration or course material, you can entirely customize the trainings depending on the learning requirements
360º Learning Solution
Be it schedule, duration or course material, you can entirely customize the trainings depending on the learning requirements
Learning Assessment
Be it schedule, duration or course material, you can entirely customize the trainings depending on the learning requirements
Certification Training Achievements: Recognizing Professional Expertise
Multisoft Systems is the “one-top learning platform” for everyone. Get trained with certified industry experts and receive a globally-recognized training certificate. Some Multisoft Training Certificate Features :
- Globally recognized certificate
- Course ID & Course Name
- Certificate with Date of Issuance
- Name and Digital Signature of the Awardee
SPSS Training Trainer Profile
11+ Years Experienced
Our SPSS Corporate & Certification Program trainers bring 13+ years of proven industry expertise, delivering practical insights aligned with real project environments.
Trained 3299+ Professionals
Our expert trainers have successfully trained 3350+ professionals through structured, real-time training programs designed for industry readiness and career growth.
Certified Experts & Real-Time Project Learning
Build strong practical skills through live project-based training sessions led by certified industry experts with real-world experience.
Hands-on Learning Approach
Gain practical exposure through real-time scenarios, industry case studies, and hands-on assignments that simulate actual project challenges.
Certification Training Guidance
Receive expert support to prepare effectively, practice strategically, and confidently achieve globally recognized certification success.
Customized Training Delivery
Flexible training approach tailored to individual learning goals, skill levels, and evolving industry requirements for maximum effectiveness.
What Attendees are Saying
Our clients love working with us! They appreciate our expertise, excellent communication, and exceptional results. Trustworthy partners for business success.
Share Feedback Download Curriculum
Download Curriculum

