Apache Spark Training
 1K+ Reviews
1K+ ReviewsInstructor-Led Training Parameters
Course Highlights
- Instructor-led Online Training
- Project Based Learning
- Certified & Experienced Trainers
- Course Completion Certificate
- Customized Learning Schedule
- Doubt-Clearing Sessions
Apache Spark Training Course Overview
The Apache Spark: It is an open source processing engine that builds around the speed, the ease of use, and the analytics. This has better efficiency than MapReduce program because it can process large amounts of data, which is required to lessen the latency processing, which is quite common in the MapReduce.
Following benefits that a candidate can learn by attending the Apache Spark course:
- Know how the Spark performs at the speeds of up to 100 times faster than Map Reduce for iterative algorithms or interactive data mining.
- Know how the Spark provides the in-memory cluster computing for lightning speed and supports Java, Python, R, and Scala APIs for ease of development.
- Know how it can tackle the wide range of data processing scenarios by combining SQL, streaming and complex analytics together seamlessly in the same application.
- Know how the Spark can run on the top of the technologies like: Hadoop, Mesos, standalone, or in the cloud. Moreover, It can access various data sources likewise: HDFS, Cassandra, HBase, or S3.
- The aspirants with software development background, who want to gain acquaintance in big data analysis will want to check this out. This course focuses on Spark from a software development standpoint.
- The software developers, who is responsible for processing the large amounts of data
- The aspirants want to learn something for a new career in data science or big data, Spark is the important part of it.
The candidates should have awareness about the fundamentals of Hadoop.
Instructor-led Training Live Online Classes
Suitable batches for you
| Jul, 2026 | Weekdays | Mon-Fri | Enquire Now |
| Weekend | Sat-Sun | Enquire Now | |
| Aug, 2026 | Weekdays | Mon-Fri | Enquire Now |
| Weekend | Sat-Sun | Enquire Now |
Apache Spark Training Course Content
1. An Introduction to Spark
- What is Spark and what is its purpose?
- Components of the Spark unified stack
- Resilient Distributed Dataset (RDD)
- Downloading and installing Spark standalone
- Scala and Python overview
- Launching and using Spark’s Scala and Python shell ©
2. About Resilient Distributed Dataset and DataFrames
- Understand how to create parallelized collections and external datasets
- Work with Resilient Distributed Dataset (RDD) operations
- Utilize shared variables and key-value pairs
3. The Spark application programming
- Understand the purpose and usage of the SparkContext
- Initialize Spark with the various programming languages
- Describe and run some Spark examples
- Pass functions to Spark
- Create and run a Spark standalone application
- Submit applications to the cluster
4. An Introduction to Spark libraries
- Understand and use the various Spark libraries
5. About Spark configuration, monitoring and tuning
- Understand components of the Spark cluster
- Configure Spark to modify the Spark properties, environmental variables, or logging properties
- Monitor Spark using the web UIs, metrics, and external instrumentation
- Understand performance tuning considerations

Request for Enquiry
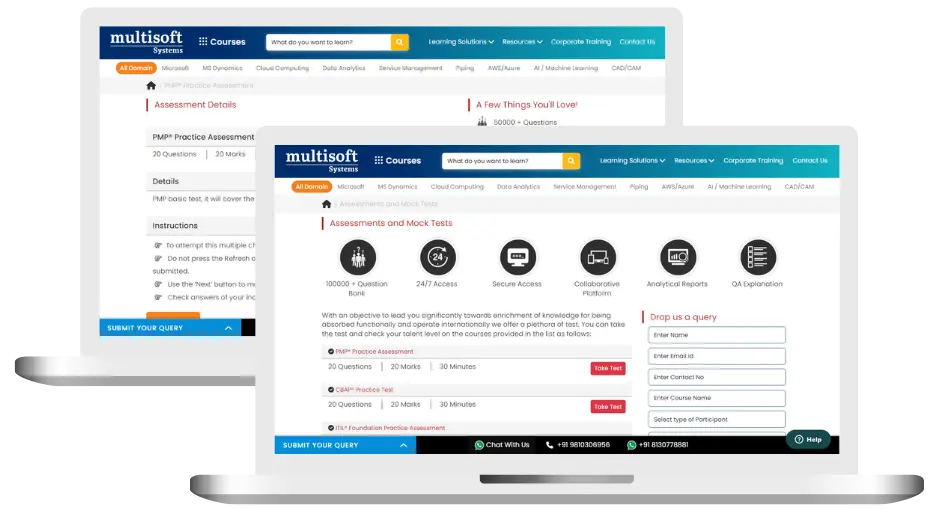
Apache Spark Training (MCQ) Assessment
This assessment tests understanding of course content through MCQ and short answers, analytical thinking, problem-solving abilities, and effective communication of ideas. Some Multisoft Assessment Features :
- User-friendly interface for easy navigation
- Secure login and authentication measures to protect data
- Automated scoring and grading to save time
- Time limits and countdown timers to manage duration.
Apache Spark Corporate Training
Employee training and development programs are essential to the success of businesses worldwide. With our best-in-class corporate trainings you can enhance employee productivity and increase efficiency of your organization. Created by global subject matter experts, we offer highest quality content that are tailored to match your company’s learning goals and budget.
Global Clients



Customized Training
Be it schedule, duration or course material, you can entirely customize the trainings depending on the learning requirements
Expert
Mentors
Be it schedule, duration or course material, you can entirely customize the trainings depending on the learning requirements
360º Learning Solution
Be it schedule, duration or course material, you can entirely customize the trainings depending on the learning requirements
Learning Assessment
Be it schedule, duration or course material, you can entirely customize the trainings depending on the learning requirements
Certification Training Achievements: Recognizing Professional Expertise
Multisoft Systems is the “one-top learning platform” for everyone. Get trained with certified industry experts and receive a globally-recognized training certificate. Some Multisoft Training Certificate Features :
- Globally recognized certificate
- Course ID & Course Name
- Certificate with Date of Issuance
- Name and Digital Signature of the Awardee
Apache Spark Training Trainer Profile
19+ Years Experienced
Our Apache Spark Corporate & Certification Program trainers bring 13+ years of proven industry expertise, delivering practical insights aligned with real project environments.
Trained 3950+ Professionals
Our expert trainers have successfully trained 3350+ professionals through structured, real-time training programs designed for industry readiness and career growth.
Certified Experts & Real-Time Project Learning
Build strong practical skills through live project-based training sessions led by certified industry experts with real-world experience.
Hands-on Learning Approach
Gain practical exposure through real-time scenarios, industry case studies, and hands-on assignments that simulate actual project challenges.
Certification Training Guidance
Receive expert support to prepare effectively, practice strategically, and confidently achieve globally recognized certification success.
Customized Training Delivery
Flexible training approach tailored to individual learning goals, skill levels, and evolving industry requirements for maximum effectiveness.
What Attendees are Saying
Our clients love working with us! They appreciate our expertise, excellent communication, and exceptional results. Trustworthy partners for business success.
Share Feedback Download Curriculum
Download Curriculum

